Pycaret AutoML으로 ensemble 하는법
Kaggle이나 Dacon 같은 AI대회에 참여하다 보면 Ensemble 기법을 사용하여 점수를 끌어올려야 하는 상황이 발생한다.
이번에 소개할 라이브러리는 Pycaret AutoML 이다.
해당 라이브러리는 거의 모든 머신러닝 알고리즘을 사용하여 간편하게 Ensemble을 할 수 있다.
Pycaret을 사용하기 위해 아래 라이브러리를 설치한다.
!pip install pycaret[full]
그 다음 pycaret을 import 해준다.
만약 회귀로 진행할 경우 pycaret.regression으로 변경한다.
from pycaret.classification import *
이제 데이터셋을 세팅해야 하는데 DataFrame 타입으로 input값을 주어야 한다.
나는 간단하게 주요 파라미터만 입력하였다.
clf = setup(data = train_df, target = 'target', train_size = 0.9, use_gpu = True, data_split_shuffle=False, normalize = True, session_id=42)data - train set
target - 종속변수(예측값)
train_size - train과 validation 비율
use_gpu - GPU 사용가능한 머신러닝 알고리즘에 적용할것인지(GPU가 있어야함)
data_split_shuffle - dataset을 무작위로 섞을것인지
normalize - 정규화를 진행할것인지
session_id - seed값

실행이 완료되면 데이터셋과 내가 세팅한 정보가 표시된다.
아래 코드를 사용하면 내가 사용할 수 있는 머신러닝 알고리즘을 알수있다.
models()
compare_models()는 모든 머신러닝 모델을 학습한 후 sort에서 지정한 평가지표에 따라
가장 높은 모델을 가져올수 있다.
n_select는 몇개의 Top 모델을 가져올것인지의 개수 다.
best_5 = compare_models(sort = 'Accuracy', n_select = 5)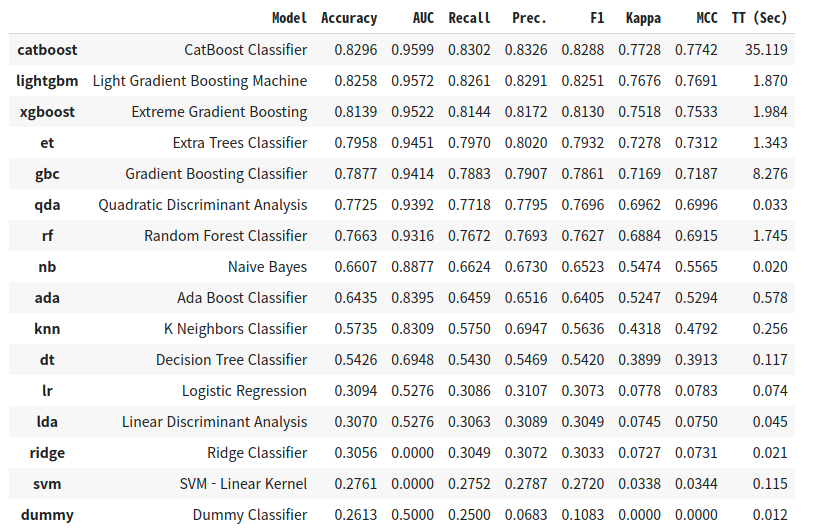
compare_models() 말고도 각각의 모델을 지정해서 학습할 수도 있다.
xgboost = create_model('xgboost', tree_method = 'gpu_hist', gpu_id = 0)
lightgbm = create_model('lightgbm', fold = 5)
rf = create_model('rf', fold = 5)
catboost = create_model('catboost', fold = 5)
lda = create_model('lda', fold = 5)
ada = create_model('ada', fold = 5)
lr = create_model('lr', fold = 5)
학습된 모델을 파라미터 튜닝할 수 있다.
sklearn의 grid search같은 기능을 한다.
기본적으로 10 fold로 평가한다.
top5 = [rank for rank in best_5]
tuned_top5 = [tune_model(i) for i in top5]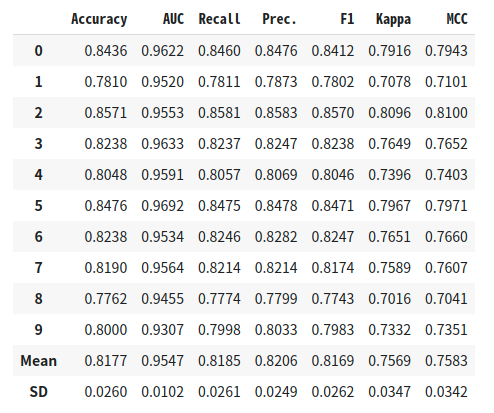
이제 마무리로 모든 모델에 voting(ensemble)을 진행한다.
blended = blend_models(estimator_list = best_5,
fold = 10,
method = 'soft',
optimize='Accuracy',
)method - 'soft' or 'hard' 기본적으로 soft가 성능이 좋기 때문에 많이 사용된다.
fold - 구간으로 나누어 검증할 횟수
optimize - 평가지표
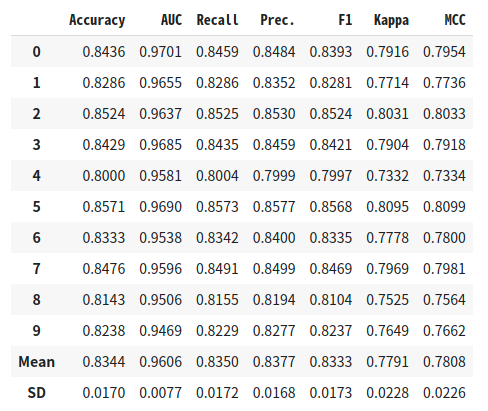
이제 학습된 ensemble 모델으로 추론을 진행해야 한다.
최종 모델을 선택한다.
final_model = finalize_model(blended)
testset을 추론한다.
predictions = predict_model(final_model, data = pd.DataFrame(test_x))
이제 score와 label로 되어있는 DataFrame을 얻을 수 있다.
score는 해당 label이 맞을 확률을 뜻한다.
predictions[['Score','Label']]
더욱 자세한 파라미터들과 사용법을 알고싶으면 아래 공식문서를 참고하면 되겠다.
https://pycaret.readthedocs.io/en/latest/api/classification.html
Classification — pycaret 2.3.5 documentation
This function transpiles trained machine learning models into native inference script in different programming languages (Python, C, Java, Go, JavaScript, Visual Basic, C#, PowerShell, R, PHP, Dart, Haskell, Ruby, F#). This functionality is very useful if
pycaret.readthedocs.io