"비슷한 값의 가중치를 굳이 따로 저장할 필요가 있을까?"
Weight Clustering(또는 Sharing)은 유사한 가중치를 묶어 모델을 추가로 압축하는 기법입니다.
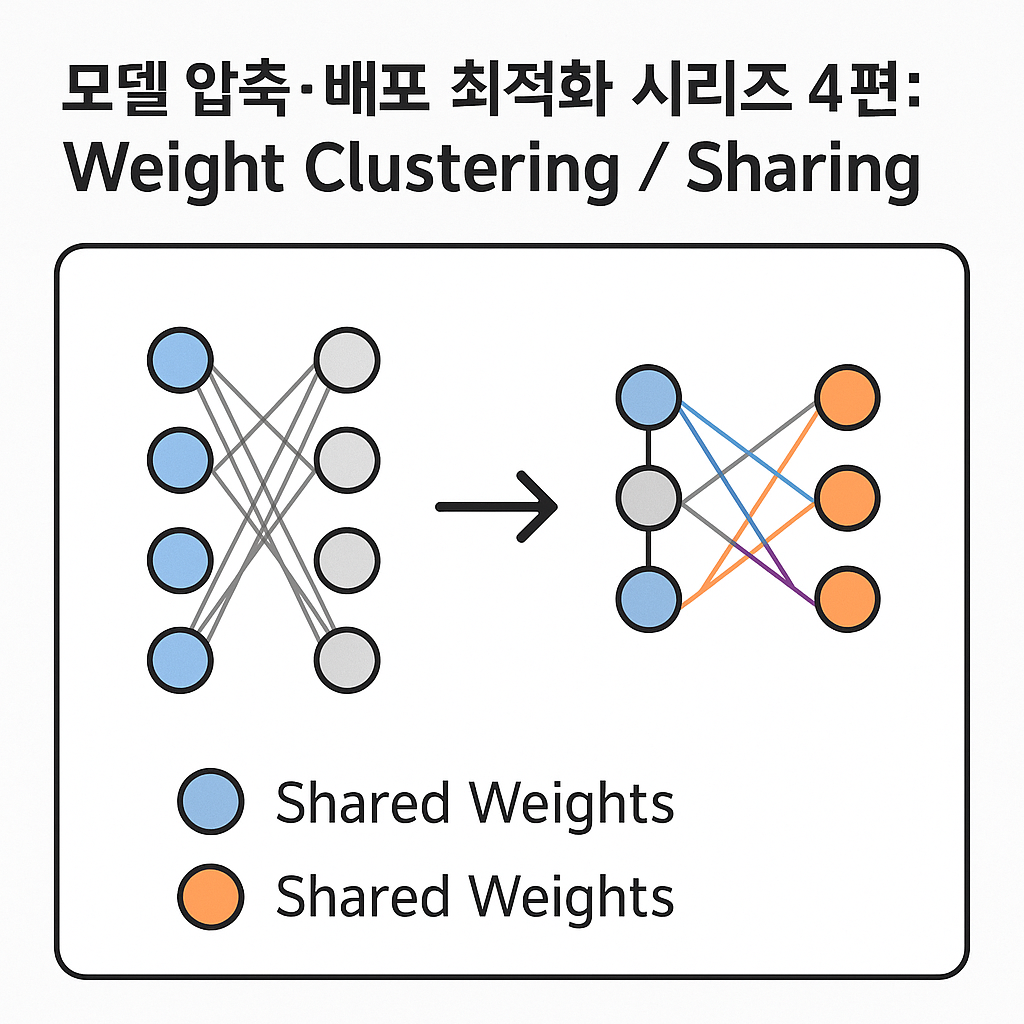
Weight Clustering / Sharing이란?
Weight Clustering은 비슷한 값을 가지는 weight들을 같은 그룹(cluster) 으로 묶고,
각 그룹의 대표값(centroid) 만 저장하는 방식입니다.
이때 모델의 실제 weight는 “클러스터 인덱스”로 참조되며,
추론 시 centroid lookup으로 실제 weight 값으로 변환됩니다.
왜 필요한가?
- 대부분의 weight 값은 특정 분포(가우시안 등)에 집중되어 있음
- 비슷한 값이 많기 때문에 중복 저장은 메모리 낭비
- Clustering으로 weight 표현을 더 압축 → 모델 크기 추가 감소
동작 원리
- 학습이 끝난 모델에서 weight 추출
- K-means 같은 알고리즘으로 weight들을 K개의 클러스터로 묶음
- weight 값을 해당 클러스터 centroid 값으로 치환
- 모델 저장 시 weight 대신 centroid + index만 저장
장점
1. 추가 압축 가능 → Pruning/Quantization 후 더 줄일 수 있음
2. 모델 저장 용량 최소화
3. 비트 수 절감 → weight 표현을 log₂(K) 비트로 압축 가능
단점 & 고려 사항
너무 aggressive한 clustering은 정확도 하락
K 선택 중요 (K 작을수록 압축률↑, 성능↓)
추론 시 lookup 오버헤드 발생 가능 (하지만 대부분 무시 가능한 수준)
Pytorch 예시 (Weight Clustering API)
import torch
import torch.nn.utils.prune as prune
model = get_pretrained_model()
# Conv layer weight 중 30%를 L1 기준으로 pruning
prune.l1_unstructured(model.conv1, name="weight", amount=0.3)
# 실제 weight 값 확인 (많은 값이 0으로 됨)
print(model.conv1.weight)실제 효과 (논문/실험)
| 모델적용 | 적용 전 | 적용 후 | 압축률 | 정확도 변화 |
| LeNet-300-100 | 1.7 MB | 0.25 MB | 6.8× | -0.3% |
| MobileNetV2 | 14 MB | 3 MB | 4.6× | -1.0% |
Pruning + Clustering을 함께 사용하면 압축률이 10~20× 까지 가능.
실무 적용 팁
- 먼저 Pruning/Quantization으로 sparsity 확보 → Clustering으로 마무리 압축
- K값 조절 → 8~32 클러스터로 시작해서 성능-압축률 트레이드오프 실험
- 압축 후 반드시 Fine-tuning 수행 → 정확도 회복
결론
Weight Clustering / Sharing은 모델 최종 압축 단계에서 매우 유용한 기법입니다.
특히 Pruning, Quantization 이후 적용하면 모델 용량을 극단적으로 줄일 수 있으며,
엣지 디바이스 배포나 메모리 제한이 심한 환경에서 큰 효과를 발휘합니다.
다음 편은 아래에 있습니다!
https://machineindeep.tistory.com/71
모델 압축·배포 최적화 시리즈 5편: ONNX / TensorRT / TFLite 변환
"모델을 한 번만 학습하고, 모든 디바이스에서 돌리고 싶다!"ONNX, TensorRT, TFLite는 모델을 효율적으로 배포하기 위한 핵심 툴입니다.모델 배포의 문제점학습은 보통 PyTorch / TensorFlow에서 하지만배
machineindeep.tistory.com
'ML | DL > 딥러닝 방법론|실습' 카테고리의 다른 글
| 대규모 모델 학습·추론 최적화 시리즈 1편: Mixed Precision Training (AMP) (1) | 2025.09.14 |
|---|---|
| 모델 압축·배포 최적화 시리즈 5편: ONNX / TensorRT / TFLite 변환 (0) | 2025.09.14 |
| 모델 압축·배포 최적화 시리즈 3편: Pruning (가중치 가지치기) (1) | 2025.09.14 |
| 모델 압축·배포 최적화 시리즈 2편: Quantization (양자화) (1) | 2025.09.14 |
| 모델 압축·배포 최적화 시리즈 1편: Knowledge Distillation (0) | 2025.09.14 |