* 해당 코드를 참고하면서 논문을 읽으면 이해하는데 도움이 됨
github.com/vincent-thevenin/Realistic-Neural-Talking-Head-Models
vincent-thevenin/Realistic-Neural-Talking-Head-Models
My implementation of Few-Shot Adversarial Learning of Realistic Neural Talking Head Models (Egor Zakharov et al.). - vincent-thevenin/Realistic-Neural-Talking-Head-Models
github.com
1. Introduction
2019년 5월에 모스크바의 Samsung AI Centor 에서 발표한 논문이다.
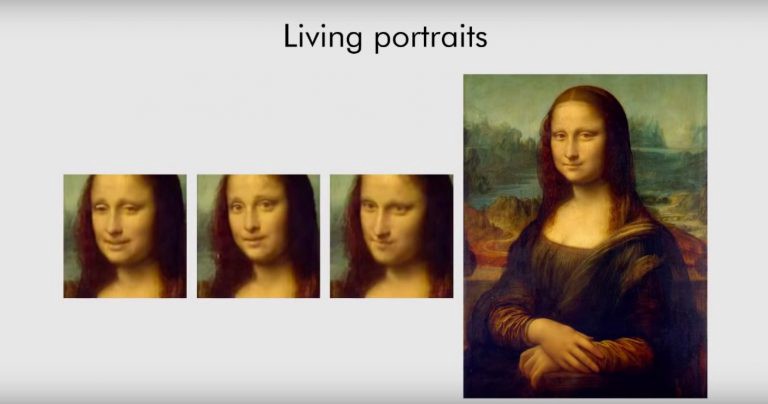
동영상과 같은 video에서 표정을 추출해내 단 한장의 이미지에 표정을 입힐 수 있는 model 이다.
(few-shot learning)
1.퓨샷 러닝(few-shot learning) 연구 동향을 소개합니다. - 카카오브레인
카카오브레인 AutoLearn 연구팀은 데이터 수가 매우 적은 상황에서도 모델을 훈련시킬 수 있는 퓨샷 러닝(few-shot learning) 연구를 진행하고 있습니다. 퓨샷 러닝에 대한 간략한 개념을 설명하고, 자
www.kakaobrain.com
talking head model은 얼굴뿐만 아니라 주변 배경, 머리카락, 옷 같은 것도 같이 움직여야 하는데
이러한 작업을 하는 것은 매우 어렵다고 한다.
하지만 활발한 연구진행으로 이 논문 처럼 현실적인 talking head model을 사용하는 논문들이 등장하고 있다.
2. Architecture Overview
few-shot 학습을 위해 Voxceleb 이라는 유명인들의 얼굴 video가 약 14만개 있는 데이터셋을 사용하였다.
한 video당 K개의 프레임을 추출하여 학습을 하였고, 논문에서는 큰 맥락으로 meta-training(학습), fine-tuning(추론)
으로 나뉘는데, meta-training 단계에서는 다양한 인물 video를 model에서 학습시켜 일반화 시키는 방법을 얻는다.
이 단계에서 얻은 model로 finetuning 단계에서 단 한장의 이미지로 빠르게 추론할 수 있게 된다.

일반적인 GAN과 달리 Generator, Discriminator 두가지 model만 존재하는게 아니라, Embedder라는 모델이 하나 추가됐다. Embedder의 역할은 사진에 보이는 것 처럼 True image, Landmark 두 가지를 model에 넣어 maxpooling으로 크기를 줄여주고, K개 frame의 평균값을 구하여 이미지의 대표적인 벡터를 얻을 수 있게된다. 그 다음 embedder vector를 MLP 층을 통과시켜 생성자인 Generator의 AadIN에 input값으로 projection 하고 Landmark와 함께 학습을 하여 False image를 생성해낸다. 이 때 loss를 Content Loss, Adversarial Loss, Match Loss를 사용하였다.
* AdaIN : content input x와 style inpu y를 받아, x의 channel-wise 평균과 분산을 y의 평균과 분산으로 매칭

Content Loss는 True image와 False image의 거리를 측정하고, VGG19, VGGFace 두 모델의 Loss를 합하여 사용하였다고 한다.
Adversarial Loss는 False image를 input값으로 Discriminator 층을 통과해서 realism score를 구하고 r_hat을 구하고
w0와 b로 r_hat과 landmark 가 일치 정도를 파악하는데 사용하였다.
여기에 FM Loss가 하나 붙어있는데 Discriminator True image, False image를 각 input 값으로 넣어 Layer 마다 나온 값들을 통해 현실적인 이미지인지 측정하는 역할을 한다.
Match Loss는 Discriminator 층에서 내부적으로 Wi 라는 각 video를 대표하는 vector를 저장해놓는데 이 vector 값들과
embedder vector의 L1(멘하튼거리) 거리에 패널티를 줘서 두 embedding이 비슷하도록 유도한다.
(어느 새로운 image나 video도 fine-tuning 단계에서 바로 사용할 수 있도록 한다.)

Discriminator는 판별자의 역할을 하며, Wi와 True나 False image를 통해서 realism score를 만들어낸다.
hinge loss(SVM에서 사용하는)를 사용한다. 두가지 loss중 하나는 True image를 input값으로 나오는 r값(1보다 크도록), False image를 input값으로 넣어 나오는 r_hat값(-1보다 작도록) 학습한다.
마지막으로 Fine-tuning 단계에서는
학습을 완료한 Embedder에 표정을 입히고 싶은 image나 video를 input값으로 넣어 meta-training단계와 똑같이 학습을 하여 각 frame에 대표적인 특성을 얻어낸다. 이 때 Generator의 파라미터값을 그대로 사용하기 때문에 identity gap이 발생한다. 그래서 Generator에 projection 하지 않고 embedder vector를 그대로 사용한다.
Discriminator에서는 새로운 image나 video이기 때문에 Wi값이 존재하지 않는다 이 값은 W' 으로 W0와 embedder vector를 sum한 값이다. 이대로 학습을 계속해서 한 인물에 대한 전체적인 특성을 얻어낸다.

'Few-Shot Adversarial Learning of Realistic Neural Talking Head Models' (arXiv, Submitted on 20 May 2019)



댓글