2020년에 강남대 데이터사이언스 전공에서 졸업작품으로 진행했던 프로젝트
'강남대 에브리타임 데이터 분석' 프로젝트를 정리할겸 블로그에도 써보기로 했다..
지금도 잘하지는 않지만 프로젝트 코드를 다시보니 답이없긴 하다 ㅋㅋ
변명을 하자면 그 당시에 나는 다른 전공에서 편입을 한거라 초보중에 초보였다..
그래도 에브리타임 분석을 진행하시려는 분들에게 참고가 됐으면 하는 바램이다.
나는 강남대 에브리타임에서 '자유게시판' 그리고 '새내기게시판'을 크롤링해서
간단한 데이터분석을 진행하였고, 게시글을 각각 주제에 맞춰서 labeling을 한 후에
multi classification으로 주제를 예측하는 것이였다.
* 참고로 크롤링 오래하면 에브리타임 측에서 차단을 먹인다.
코드는 여기있으니 참고하시길
https://github.com/YongSeongLee25/KNU_Everytime_python
GitHub - YongSeongLee25/KNU_Everytime_python
Contribute to YongSeongLee25/KNU_Everytime_python development by creating an account on GitHub.
github.com
1. EDA
1.1 데이터 불러오기
크롤링한 데이터는 '시간', '내용', '좋아요 수', '댓글 수'
csv file을 데이터프레임 형태로 만들었다.

1.2 데이터 개수 확인
2020년까지의 모든 게시글을 추출했다.
새내기 게시판 - 16,820개 dataset
자유 게시판 - 110,399개 dataset

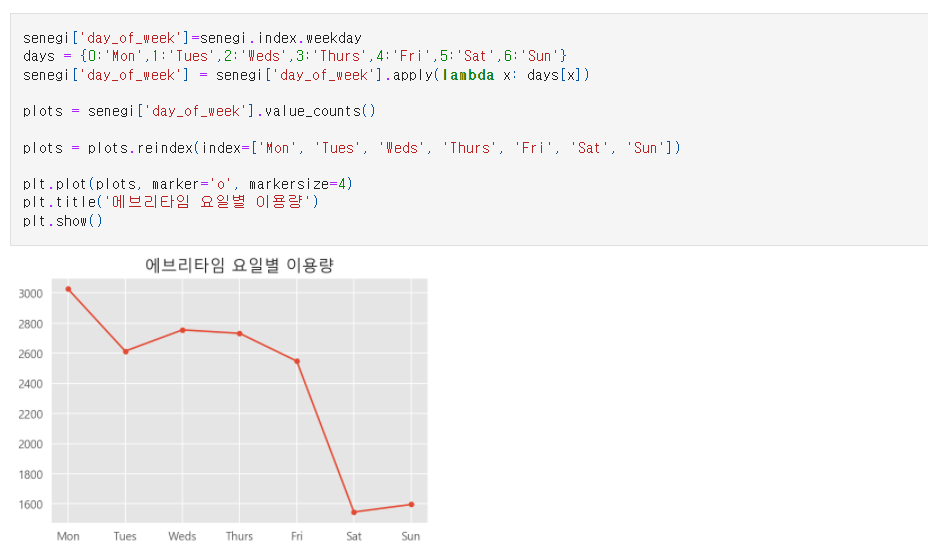
1.3 에브리타임 이용량
시간별 이용량

요일별 이용량
월별 이용량

1.4 분기마다 제일 많이 나온 단어

1.5 전체 게시글에서 가장많이 쓰인 단어

1.6 게시글의 길이

2. Labeling
0 - 기타, 1 - 행정, 2 - 교양, 3 - 교양필수, 4 - 경영, 5 - 복지, 6 - 글로벌, 7 - ict, 8 - 사범, 9 - 캠퍼스관련
강남대 과를 위주로 해서 labeling을 했는데 데이터의 불균형이 많이 심하다..그래서 SMOTE 알고리즘으로
UpSampling도 시도했었는데현재 해당 알고리즘이 잘못된 방법이다 라고 욕을 먹고 있어서 올리진 않겠다.

3. 데이터 전처리
게시글의 내용 column를 학습데이터로 사용하기 위해
konlpy의 Okt 라이브러리로 명사, 동사, 형용사만 추출하도록 한다.

그 다음에는 TfidfVectorizer를 이용해 자연어를 학습가능한 형태로 임베딩한다.

4. 모델학습
GridSearchCV를 최적의 파라미터를 이용해서xgboost를 사용해서 학습했다.
그래도 0.93%로 잘 예측한 것 같다.

5. 결론
원래는 에브리타임에서 게시글에 자동응답하는 봇을 만드려했으나 크롤링하다 차단을 당해서
하지는 못했고.. 대체방법으로 학습한 모델을 이용해 flutter기반 자동응답 앱을 만들었는데 모델을
실제로는 쓸만하지 못하다 판단해 구글앱스토어엔 등록하지 않았다.
지금와서는 개선해야할 사항이 많이 보이긴 하지만
더 이상 에브리타임을 크롤링할 수 없기 때문에
이 프로젝트는 과거의 경험으로만 남겨두는걸로
'ML | DL > ML DL 프로젝트' 카테고리의 다른 글
| [Kaggle] 타이타닉 생존자 예측 도전 (0) | 2020.09.20 |
|---|