반응형
Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspective
논문의 내용을 요약한 것 입니다.
연구 배경 & 문제의식
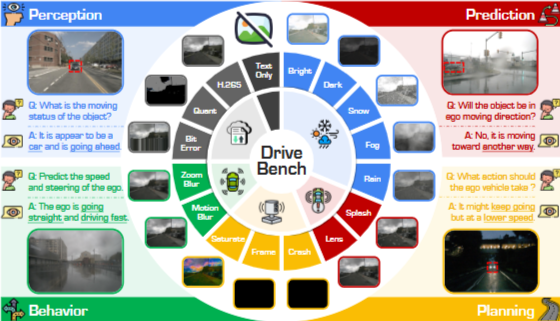
자율주행 시스템에 VLM(Vision-Language Model)을 적용하려면 신뢰성이 핵심입니다.
하지만 지금까지의 연구는 “VLM이 자율주행 시나리오에서 해석 가능한 의사결정을 제공할 것”이라는 가정만 있었을 뿐,
시각적 근거가 얼마나 탄탄한지 체계적으로 검증하지 않았습니다.
이 논문은 DriveBench라는 새로운 벤치마크 데이터셋을 만들어,
VLM이 실제 주행에서 얼마나 믿을 만한 답변을 내놓는지 평가합니다.
DriveBench: 데이터셋 & 벤치마크
- 구성:
- 총 19,200 프레임 + 20,498 Q&A 쌍
- 17가지 입력 환경 (깨끗한, 손상된, 텍스트 전용 등)
- 4대 주요 자율주행 작업: 인지, 예측, 계획, 행동
- 3가지 질문 유형: 다지선다형, 개방형, 시각적 근거(grounding)
- 편향 완화:
- 기존 DriveLM 데이터셋의 Going Straight(직진) 과다 비중(>78%) 문제 지적
- 재샘플링으로 정답 분포 균형 맞춤 → 무작위 선택으로 높은 점수 나오는 문제 방지
- GPT-4o로 “시각적 단서가 충분한 샘플”만 골라 평가 정확도 개선
다양한 시각 손상 시뮬레이션
DriveBench는 실제 자율주행 상황에서 발생할 수 있는
**15가지 손상(corruption)**을 도입해 VLM의 강건성(OoD 성능)을 평가합니다.
- 기상: 밝음/어두움/눈/안개/비
- 방해 요소: 물 튐, 렌즈 가림
- 센서 문제: 카메라 고장, 프레임 손실, 채도 포화
- 모션: 모션 블러, 줌 블러
- 전송 오류: 비트 오류, 색 양자화, H.265 압축
충실도 합성 알고리즘으로 만들어 실제 도로 상황과 유사하게 재현
평가 지표 & 루브릭
단순 Accuracy나 BLEU로는 부족하기 때문에,
GPT 기반 채점(GPT score) + 세부 루브릭을 설계해 평가했습니다.
- 다지선다형: 정답 정확도(50), 객체 인식(10), 위치/방향(15), 환경 인식(15), 추론 명확성(10)
- 개방형: 행동 일치(20), 움직임 정밀도(20), 맥락 적합성(15), 상황 인식(15), 간결성(20), 문법(10)
주요 실험 결과 & 인사이트
- 손상된 시각 입력 → 조작된 응답
- VLM은 시각 정보가 없거나 손상되면 그럴듯하지만 근거 없는 답변을 생성
- 기존 데이터셋으로는 이 문제를 탐지하기 어려움
- 손상 인식은 제한적
- 명시적으로 "손상됐다"라고 프롬프트할 때만 인식
- 그렇지 않으면 일반 지식으로 답변 → 위험한 의사결정 가능성
- 데이터셋 편향 영향
- 직진 비율 과다 → “무조건 직진”만 해도 높은 점수
- 재샘플링으로 이런 허상을 줄이고 더 균형 잡힌 평가 가능
- 맞춤형 지표 필요성
- BLEU, ROUGE-L, GPT score만으로는 안전·상황 이해의 미묘한 차이를 잡기 힘듦
- 더 정교한 안전 중심 지표 필요
비판점 & 한계
- 실제 도로 주행 테스트 부족
- 합성·재구성 데이터 기반 → 실제 복잡한 도로 상황 반영 한계
- GPT 기반 채점의 주관성
- GPT 평가자가 맥락을 잘못 해석하면 점수 왜곡 가능
- GPT 모델 자체가 편향을 내포할 수 있음
- 실시간성 고려 부족
- 자율주행에서 중요한 추론 지연(latency) 측정 미흡
- 데이터 중복 문제
- 사전 학습 데이터와 중복 가능성 → 완전한 제로샷 평가 보장 어려움
앞으로의 연구 방향
- 실차 주행 테스트 연계
- 시뮬레이션 + 실제 도로 주행 데이터 결합 → 현장 검증 강화
- 시각-센서 융합(Vision+Sensor Fusion)
- LiDAR, RADAR, V2X 데이터까지 통합해 멀티모달 신뢰성 확보
- 실시간 평가 지표 도입
- 정확도뿐 아니라 **응답 시간(latency)**과 연속 프레임 일관성까지 평가
- 안전 중심 메트릭 개발
- “실제 사고 위험 감소”에 초점을 둔 지표 설계 (예: 위험 회피율, 안전 마진 유지율)
- 모델 불확실성 추정
- VLM 출력의 신뢰도(score) 산출 → 불확실할 땐 "모르겠다" 응답 가능하게 설계
한줄 코멘트
이 논문은 VLM의 '착시 효과'를 벗겨내고,
자율주행 적용 전 반드시 거쳐야 할 평가 단계를 제시한다.
앞으로는 안전 중심·실시간·멀티센서 방향으로 연구가 확장될 필요가 있다.
좀 더 자세한 것은 아래 논문에서
반응형
'ML | DL > 딥러닝 논문' 카테고리의 다른 글
| 5분 컷 논문 리뷰: Easy Dataset – 비정형 문서를 LLM 학습 데이터로 바꾸는 통합 파이프라인 (1) | 2025.09.15 |
|---|---|
| 5분 컷 논문 리뷰: VLM-R1 – R1 스타일 RL로 시각적 추론 강화하기 (1) | 2025.09.15 |
| 5분 컷 논문 리뷰: FastVLM으로 VLM 85배 빠르게 만들기 (1) | 2025.09.15 |
| PBNS(Physically Based Neural Simulation for Unsupervised Outfit Pose Space Deformation) 논문 리뷰 (0) | 2024.04.11 |
| CLIP(Contrastive Language-Image Pre-Training) 논문 리뷰 (0) | 2024.04.11 |